人声编码器(voice encoder),简称声码器,又称语音信号分析合成系统,对声音进行分析与合成的系统,主要应用于合成人类语音。此编码器主要的概念是将声音编码之后再进行传输,允许更多的语音频道共享同一个的无线电电路或海底电缆。人声编码器可以用硬件或软件的方式来实现。
精选百科
本文由作者推荐

人声编码器
人声编码器
外文名
voice encoder
学科
计算机技术
应用
合成人类语音
简介
语音是人类最直接、最高效的信息交流手段。在通信技术的发展过程中,语音通话一直是大多数通信系统的基本功能。信息传输的内容开始向多样化的方向发展,图像、视频等非语音信息在通信中占据的比例逐渐增大,但是语音通话以其便宜、便捷等特点仍然是使用最多的通信方式,因此有效地传递语音信息仍然是众多通信系统的必备功能之一。在数字通信系统中,原始语音信号必须经过数字化后才能传输,但数字化后的语音信号存在大量冗余。对语音信号进行编码能够有效地去除数字语音信号中的冗余信息,降低编码速率,因此语音编码技术在现代通信系统中有着广泛地应用。
人声编码器或声码器,一种语音信号编码译码器。利用语音信号模型语音分析合成的系统。传播时只利用模型参数,编译码时利用模型参数估计和语音合成技术。其语音模型中,语音被看作为一个快速变化的激励信号送入一个缓慢变化的声道滤波器后所得的输出。激励信号在清音时为噪声,浊音时为具有基音周期的脉冲串。语音模型中的语音信号用两组参数表示。一组为激励源参数,包括清浊音指示、基音频率和振幅;另一组为声道滤波器的响应参数,参数不同,声码器类型也不同。传输的是去除了语音信号中冗余度的模型参数。压缩比大,但也因丢失了语音的某些细节,给语音信号的自然度带来较大影响。已研究出来的声码器有通道声码器、共振峰声码器、同态声码器、线性预测声码器和音素声码器。声码器早期应用于军事通信,压缩比虽大,但重建语音质量较差。采用线性预测的声码器在语音质量上已可达到电话通信的要求,在移动通信、话音存储转发和可视电话等领域具有广泛的应用前景。
声码器的明显优点是数码率低,因而适合于窄带、昂贵和劣质信道条件下的数字电话通信,能满足节约频带、节省功率和抗干扰编码的要求。低数码率对话音存储和话音加密处理也都很有利。声码器的缺点是音质不如普通数字电话好,而且工作过程较复杂,造价较高。现代声码器主要用于军队、政府以及那些值得付出代价以换取通信安全(保密)的场合。随着对人类发声机构和听觉机理的深入研究以及计算机技术和大规模集成电路的发展,声码器的音质和设备小型化将不断得到改进,并将在数字通信中得到更广泛的应用。
声码器对话音存储和话音加密处理很有利、有算法,速度快、质量好且结构简单、适合于窄带、昂贵和劣质信道条件下的数字电话通信。但工作过程复杂,价格高,音质有点差。
理论
人讲话时,人声是由喉头的声带开关声门所产生,其中包括了许多周期性的波形与许多谐波,这些周期波可视为基本的声源信号。这些声源信号接着经由鼻子和喉咙(可视为复杂的共振系统),借由改变嘴型来改变此系统,而产生不同的谐波含量,创造了各式各样的语音;另外浊音与塞音则是气流经由不同嘴型产生。声码器发信端的分析器对话音信号进行分析,将该信号被分裂成多个频带(这个数字越大,会得到更准确的分析)。输入信号通过一个多频带滤波器,并将每个频带分别通过一个包络检测器,将包络检测器得到的控制信号输出给解码器。由于控制信号与原来的语音波形相比变化速度缓慢许多,因此声码器大幅降低了语音传输所需的频带。若将控制信号进行加密,则可以保证语音传输安全性,以防拦截。比起原始的语音资料,大约可将传输资料压缩到原先的十几分之一。语音信号的重建则将步骤反转;接收端接到每个频带的包络线参数以后,分别得到每个频带的包络线,可视为多个随时变的滤波器。接着由一个新的“丰富频率成分”的声源信号(可视为噪音讯号),通过每个频带的滤波器得到每个频带的包络线讯号,最后将这些讯号得加,得到还原语音讯号。值得注意的是,通过以上的编码方法,丢弃了许多原本信号的资讯,主要丢弃了信息频谱的瞬时频率,也就是频谱的相位。这样的资讯流失虽然保留了语音的可辨识度,但相位的遗失意味着音高的遗失,如中文的“平、上、去、入”等五声的资讯将遗失,而听起来的声音会像机器人讲话一般,没有“抑扬顿挫”。这种“机器人式”的特殊音色,在流行音乐和音效娱乐受到欢迎,在电子音乐中广泛的被应用。
类型
1939年以后,已经制出的声码器主要有:通道声码器、共振峰声码器、同态声码器、线性预测声码器和音素声码器。
通道声码器:在这种声码器中,输入语音信号的幅度谱通过由14~20个带通滤波器所组成的滤波器组进行分析,滤波器组把频率范围分成许多相邻频带或通道,每个滤波器的输出都是一个包络缓慢变化的信号,包络的大小反映了该频带内信号的功率。所以各带通滤波器输出的包络总起来就能近似表示语音信号的幅度谱。另一方面基音检测和清浊音鉴别器提供基音周期和清油音指示。在译码端,有与编码端相同的滤波器组。淸浊音指示用于选择滤波器组的激励源,浊音时用脉冲串,清音时用噪声。脉冲串的频率由基音控制,谱包络信息则用来控制各滤波器输出的大小,因而最终能合成与原始谱包络相近的语音信号。通道声码器的语音质量,即使在2.4kbit/s速率下也可以达到相当高的清晰度,且抗背景噪声的能力强,稳定性好,因而得到了广泛的应用,对它的兴趣多年不衰。
共振峰声码器:是通道声码器的一种变型,它在编码的是共振峰频率和带宽。根据听觉试验的结论,一般只需传送3~4个共振峰,因此可以达到很低的数据率。当共振峰提取正确时,共振峰声码器可以在语音质量上超过通道声码器而速率只需后者的一半。只是由于正确跟踪共振峰频率在实现时相当困难,阻碍了这种声码器的实用,但对它的研究始终不断。
同态声码器:又称倒谱声码器,它传送的模型参数是语音的倒谱和语音的幅度谱一样,可以反映声道的响应,但是在理论上,利用倒谱可以使语音模型中激励源和声道响应的参数得到理想的分离,在理论上虽是一种方法,但在实际实现时同态声码器需要很大的计算量,数据率在相同的语音质量下高于通道声码器,而且抗语音背景噪声的能力差,所以只获得有限的应用。
线性预测声码器:是应用最多的一种声码器。其最主要的特点是利用线性预测对声道的响应进行建模。声码器传送的参数除激励参数外,就是线性预测系数。典型的线性预测系数代表了声道的冲激响应,但是语音质量对这些系数的量化非常敏感,每个参数要求的比特数也较多,所以在实用时往往使用各种等价的但要求量化比特数少且对比特数不敏感的参数,如反射系数和线谱对等。线性预测声码器的激励模型现已得到改进,如采用浊音声门波激励模型或多脉冲激励模型等。在进行这些改进后,线性预测声码器的语音质量在声码器中居于前列。
音素声码器:声码器中速率最低的一种,主要由音素识别器与音素综合器组成。但实际使用的语音单位一般不是音素而是复合音素等较大的语音单位,因为不考虑上下文影响而连接的音素串是不可懂的。这种声码器的语音质量基本上已完全失去自然度,声码器所需的数据速率则可在200bit/s以下。
在声码器历史上还出现过相关声码器、相位声码器以及由F.莫策提出的莫策声码器等。其中相位声码器,虽然在一般文献上把它归入声码器,实际上属于子备编码。它和相关声码器都没有得到实际应用,只有莫策声码器获得一些应用。
人声编码器相关的文章

木卫二(Europa,古希腊语:Ευρώπη),又称为欧罗巴,是木星的第六颗已知卫星,也是木星的第四大卫星。在1610年被伽利略发现后,木卫二由西门·马里乌斯独立发现。木卫二的公转轨道距离木星第五近,稍微比月球小。 木卫二是一个温和的世界,表面覆盖着冰层,底层是一片海洋。科学家认为,地球上海洋孕育了
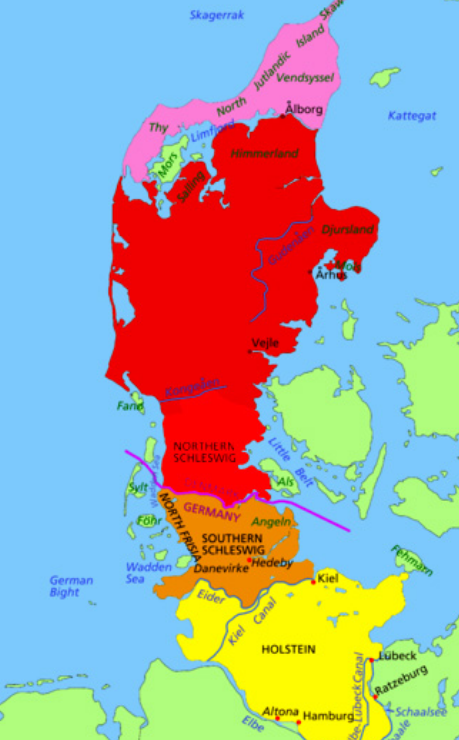
日德兰半岛(英文:Jutland;德文:Jütland;丹麦文:Jylland;低地德文:Jö;tlann),是欧洲北部的半岛,面积约25485平方公里,位于北海和波罗的海之间,构成丹麦国土的大部分。西和北为北海和斯卡格拉克海峡,东为卡特加特海峡和小贝尔特海峡。人口约235万。古代地理上称为西姆布里卡半岛。从广义上说,包括德国石勒苏益格-荷尔斯泰因州。

尚可名片
这家伙太懒了,什么都没写!
作者