
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
精选百科
本文由作者推荐
布隆过滤器
1970年由布隆提出的概念
中文名
布隆过滤器
外文名
Bloom Filter
提出者
布隆
提出时间
1970年
基本概念
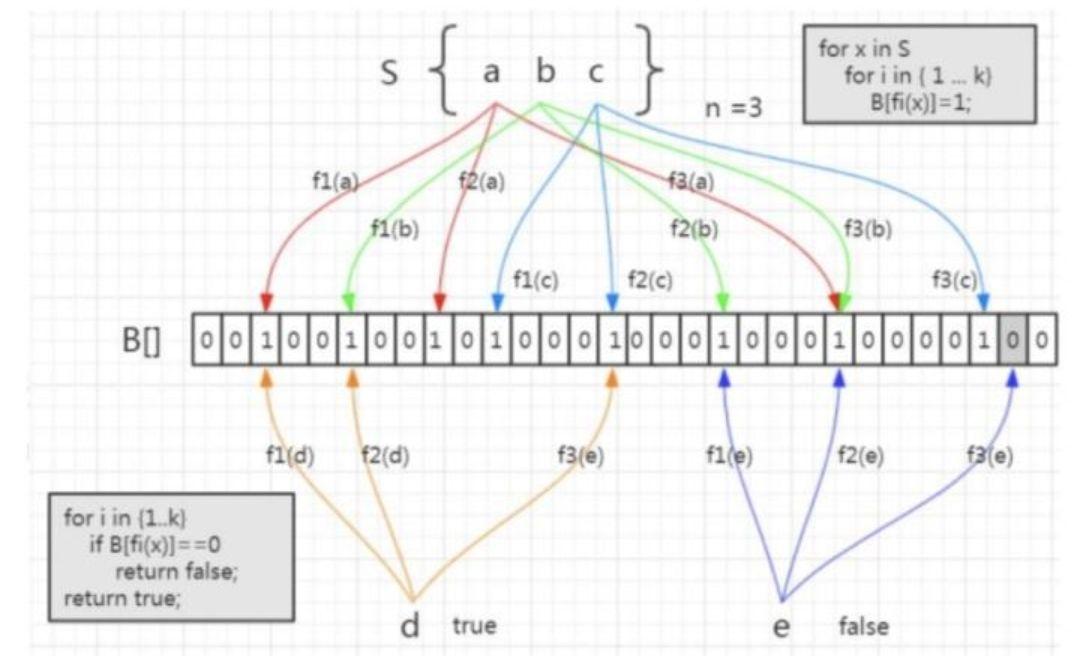
如果想要判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢

Hash面临的问题就是冲突。假设Hash函数是良好的,如果我们的位阵列长度为m个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳


布隆过滤器
优点
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数。另外, Hash函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
布隆过滤器可以表示全集,其它任何数据结构都不能。
缺点
但是布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。常见的补救办法是建立一个小的白名单,存储那些可能被误判的元素。但是如果元素数量太少,则使用散列表足矣。
另外,一般情况下不能从布隆过滤器中删除元素。我们很容易想到把位列阵变成整数数组,每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就可以了。然而要保证安全的删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
在降低误算率方面,有不少工作,使得出现了很多布隆过滤器的变种。
应用
网页URL的去重,垃圾邮件的判别,集合重复元素的判别,查询加速(比如基于key-value的存储系统)、数据库防止查询击穿,使用BloomFilter来减少不存在的行或列的磁盘查找。
java代码实现
| 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485868788899091929394959697 | public class MyBloomFilter { /** * 一个长度为10 亿的比特位 */ private static final int DEFAULT_SIZE = 256 << 22; /** * 为了降低错误率,使用加法hash算法,所以定义一个8个元素的质数数组 */ private static final int[] seeds = {3, 5, 7, 11, 13, 31, 37, 61}; /** * 相当于构建 8 个不同的hash算法 */ private static HashFunction[] functions = new HashFunction[seeds.length]; /** * 初始化布隆过滤器的 bitmap */ private static BitSet bitset = new BitSet(DEFAULT_SIZE); /** * 添加数据 * * @param value 需要加入的值 */ public static void add(String value) { if (value != null) { for (HashFunction f : functions) { //计算 hash 值并修改 bitmap 中相应位置为 true bitset.set(f.hash(value), true); } } } /** * 判断相应元素是否存在 * @param value 需要判断的元素 * @return 结果 */ public static boolean contains(String value) { if (value == null) { return false; } boolean ret = true; for (HashFunction f : functions) { ret = bitset.get(f.hash(value)); //一个 hash 函数返回 false 则跳出循环 if (!ret) { break; } } return ret; } /** * 测试。。。 */ public static void main(String[] args) { for (int i = 0; i < seeds.length; i++) { functions[i] = new HashFunction(DEFAULT_SIZE, seeds[i]); } // 添加1亿数据 for (int i = 0; i < 100000000; i++) { add(String.valueOf(i)); } String id = "123456789"; add(id); System.out.println(contains(id)); // true System.out.println("" + contains("234567890")); //false }} class HashFunction { private int size; private int seed; public HashFunction(int size, int seed) { this.size = size; this.seed = seed; } public int hash(String value) { int result = 0; int len = value.length(); for (int i = 0; i < len; i++) { result = seed * result + value.charAt(i); } int r = (size - 1) & result; return (size - 1) & result; }} |
布隆过滤器相关的文章

加拿大薄荷,属于植物界,种子植物门,双子叶植物纲,唇形目,唇形科,薄荷属,花朵呈黛青色或紫罗兰色,茎株长达10-46厘米,叶对生。花序生长在上位叶的叶腋上。该种薄荷生长在潮湿地区,但不能直接生长于水中。为薄荷属下的一种薄荷。还可以用来做捕捉狐狸和猞猁的诱具。
世界气象组织(英语全称:World Meteorological Organization,简称:WMO),是联合国的一个专门机构,总部设于瑞士日内瓦,有193个会员国和会员地区(截至2023年6月) ,致力于在地球大气状态和变化规律及其与陆地和海洋的相互作用、大气产生的天气和气候、以及由此产生的水
印度河是巴基斯坦主要河流,也是巴基斯坦重要的农业灌溉水源。它的名字源自梵文Sindhu(信度)之拉丁语式拼法Indus,意为“河流”。在1947年印巴分治之前,印度河是该地区的文化和商业中心地带,仅次于恒河。印度河的总长度约为2900至3200公里。印度河文明是世界上最早进入农业文明和定居社会的主要

李治本词条是多义词,共15个义项唐朝第三位皇帝唐高宗李治(628年7月21日 -683年12月27日),字为善,唐朝第三位皇帝(649年7月15日-683年12月27日在位),唐太宗李世民第九子,母为文德顺圣皇后长孙氏,皇太子李承乾、魏王李泰同母弟。贞观二年(628年)六月,李治出生于东宫丽正殿。贞观五年(631年)封晋王,后皇太子李承乾与次子魏王李泰相继被废,于贞观十七年(643年)被册为皇太子

尚可名片
这家伙太懒了,什么都没写!
作者

