推土机处理器(Bulldozer)是Intel Nehalem开发的一种处理器,采用了“模块化”的设计,每个“模块”包含两个处理器核心,每个核心具有各自的整数调度器和四个专有的管线,两个核心共享一个浮点调度器和两个128位FMAC乘法累加器。
精选百科
本文由作者推荐

推土机处理器
Intel Nehalem开发的处理器
中文名
推土机处理器
外文名
Bulldozer
提出时间
在2007年年中提出
开发商
Intel Nehalem
简介
AMD“推土机”是代号Bulldozer(推土机)的全新架构,“推土机”架构最早是在2007年年中提出的,当时计划采用45nm工艺,2009年上半年发布,竞争Intel Nehalem,不过可能是因为45nm K10 Phenom系列进展不顺,新架构被推迟了。在AMD的发展规划中在2009-2010年间都是45nm Phenom打天下,32nm工艺产品要到2011年才会发布,也就是“推土机”架构。
“推土机”是AMD彻底重新设计的核心,将成为AMD下一代高性能处理器技术,用于客户端和服务器领域,相比于Opteron 6100系列会增加33%的核心、大约50%的性能。
作为崭新一代的处理器构架,AMD“推土机”将采用32nm SOI工艺,这让“推土机”相比“Magny-Cours”皓龙处理器可以在不增加功耗的前提下增加33%的核心数量、增加50%的吞吐量。
与AMD之前所有处理器都有所不同的是,“推土机”采用了“模块化”的设计,每个“模块”包含两个处理器核心,这有些像一个启用了SMT的单核处理器。每个核心具有各自的整数调度器和四个专有的管线,两个核心共享一个浮点调度器和两个128位FMAC乘法累加器。

“推土机”处理器

推土机FX系列处理器架构示意图
型号规格
桌面版本推土机家族的桌面版本“赞比西河”(Zambezi)将分为三个子系列,分别是八核心的FX-8000、六核心的FX-6000、四核心的FX-4000。首发型号四款,包括两款八核心、一款六核心和一款四核心;到年底的时候还会追加另外四款,主要是速度上的提升。
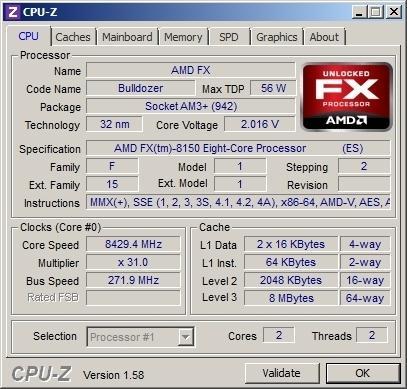
推土机FX8.429G主频破世界纪录
赞比西河都采用GlobalFoundries 32nm SOI工艺制造,Socket AM3+封装接口,首批四款都支持Turbo Core动态加速,而且全部属于Black Edition黑盒版,开放超频,内存支持均为双通道DDR3,频率最高达到了1866MHz。高端版本高端版本“FX-8130P”为四模块八核心,二级缓存8MB(每模块2MB),三级缓存最大8MB,热设计功耗125W;之下是同样八核心的“FX-8110”,应该是频率略有降低,热设计功耗也降至95W,其他相同。
六核心是“FX-6110”,三模块,二级缓存相应地减至6MB,四核心则是“FX-4110”,双模块,二级缓存4MB,热设计功耗都是95W。
具体型号型号 | FX-8130P | FX-8110 | FX-6110 | FX-4110 |
核心 | 8 | 8 | 6 | 4 |
二级缓存 | 8MB | 8MB | 6MB | 4MB |
三级缓存 | 最大8MB | 最大8MB | 最大8MB | 最大8MB |
热设计功耗 | 125W | 95W | 95W | 95W |
DDR3 内存频率 | 1866MHz | 1866MHz | 1866MHz | 1866MHz |
Bulldozer(推土机)架构中的另一个新元素就是采用了基于集群的多线程技术。Bulldozer的内核模块是一个可以同时运行两个线程的处理组件,两个内核可以执行两个完全不会相互干扰的线程,有点类似于Intel的双核处理器的超线程奇数。
多簇式多线程技术
尽管双核、多线程和Bulldozer在线程并行执行方面是相同的,但是内核的分区却截然不同。多线程就是在一个单个的处理核心内同时运行多个工作线程的技术,和CMP芯片多处理器技术不同,后者是通过集成多个处理内核的方式让系统的处理能力提升,市场上主流的多核处理器都是用了CMP技术,而像Pentium 4、Core i7这样的处理器带的“超线程技术”则属于多线程奇数,而Bulldozer是基于集群化多线程架构,Cluster-Based Multi-threading:CMT,也称多簇式多线程技术。
设计集群化
在Intel的超线程方案中,采用的是复制处理器架构状态的方法来实现超线程,核心内部并没有增设一套额外的硬件执行单元来处理多线程,只是增加了处理器中存储线程有关数据的单元数量,病在硬件执行单元空闲时将这些数据送往其中处理,一边增加处理器执行单元的利用率。这种设计有一定的缺点,比如它只使用了一个指令窗口来负责两个线程的调度、执行和引退,效率并不高。这就像是生产线只有一名管理调度人员,一个人很难同时处理两个任务,这样有时候便会出现生产线故障,而处理器在碰到这种情况时性能泽辉出现明显的下降。
相对于传统超线程或双核技术,Bulldozer这种设计集群化架构的理念是让双核模块在多线程运算中更高效。Bulldozer每一个模块中加入了额外的执行单元,每一个模块都具备可以将一个大任务细分为多个并行任务的能力,这些生产线可以按需要任意整合,不会对整个装配线的效能造成影响。因此CMT技术的效能要高于传统的多线程方案。根据AMD介绍,单个“推土机模块”可以达到80%左右的多线程性能提升,而且所用的晶体管数目似乎并不比Intel的超线程奇数更多,这是一个相当鼓舞人心的成就。
产品优势全核心技术
Turbo Core技术主要是指对于一些没有完全消耗到最大程度的工作负载,去加快时钟速度。在多种不同工作负载上,使用了Turbo Core可以最大增加500兆赫兹的性能。最重要的一点,Turbo Core加速指的是所有核的加速,和有些核加速技术明显不同,以往的核加速技术可能需要关闭一些核,只对部分核进行加速。采用Turbo Core技术,最多可以使所有核增速500兆赫兹,如果再关闭一些核运转的情况下,加速将会超过500兆赫兹。同时我们还对内存控制器进行了进一步优化,从而提高内存的吞吐量。
除了每个核心独享4个整数计算管线,在浮点运算上,“推土机”采用了“FlexFP”技术,两个核心共享一个浮点调度器和两个128位FMAC乘法累加器,可以进行组合,每个时钟周期可以完成两次64位双精度计算或4次32位单精度计算。如果一个核心没有进行浮点运算,那么另一个核心可以占用这两个128位的FMAC,在一个时钟周期完成4次双精度运算或8次单精度计算,AMD将其命名为 AVX模式。这种技术保证了“推土机”的浮点运算能力,在高性能计算中并不会因为“共享”而牺牲性能。
新接口和新工艺
推土机处理器将采用Socket AM3+接口,942个针脚,不同于938个针脚的Socket AM3接口,其好处是可以支持DDR3-1600内存和高级节能技术,而且AM3+将是AMD的最后一代针脚栅格阵列(PGA)封装,之后将改用触点栅格阵列(LGA),等到Fusion融合处理器降临的时候就会使用LGA AF1新接口,触点多达1591个,支持DisplayPort 1.2标准、PCI-E 3.0规范(32条信道)、四通道内存。
加强型内存控制器
AMD首家推出集成内存控制器,根据AMD在这一领域的经验和非常好的技术,又在这一代产品中全面提升了内存控制器的性能。首先对内存控制器在效率方面进行了针对性的重新设计和完善,因此实现30%的内存性能提升。在提升30%性能基础上,让内存支持1600MHz频率,可以获得额外20%的性能。两项加起来,可以实现内存控制器50%吞吐量提升
同时支持AVX指令和SSE指令
FLEX FP是AMD至今为止最有创新意义的浮点计算技术,每一个模块都有一个FLEX FP进行浮点运算。如果使用传统128位编码,意味着每个核会有单独的浮点运算单元。与友商相比,如果在128位编码前提下,AMD所执行的数量多一倍。如果是256位AVX编码,Bulldozer可以把两个浮点运算单元放在一起执行。所以在256位编码执行模式下,与友商比较,执行的数量是一样的。但是Bulldozer有一个非常大的优势,就是可以同时执行256位AVX指令和SSE指令。而友商就不能做到这点,他们只能在AVX或SSE中选择其一,这样的优势能够让Bulldozer在高性能计算、媒体编解码以及在一些技术型运算方面有更高的性能。
更先进的电源管理技术
每个模块内第二个整数核心所需要的电路只占总核心面积的12%,从芯片级别上讲这只会给整个内核增加5%的电路。更多的核心、更少的空间,这显然有利于提高单位功耗、单位成本的性能。
能耗大小是由被通电时钟数量决定的,它取决于执行一个普通指令(运算)需要让多少晶体管处于通电状态。在最大时钟供电的百分比下,正常应用状态和闲置状态下,Bulldozer都具有非常好的能耗表现。同时在各能耗单位上进行了优化,可以在各种单位下进行电源关闭。高性能运算能耗之所以高,主要是由于浮点运算,而一般应用运算主要是在执行单元消耗得最高。同时还有闲置状态下,AMD的技术可以做到对于那些完全用不着的核,把电源完全关闭。AMD产品有一个大转型,AMD推出了新插槽,2011年推出的推土机可以使用2010年的插槽。而友商为推出新平台,同时推出了新插槽,这也使得AMD更占优势。[1]
参考资料
1.IT168(引用日期:2019-07-10)
推土机处理器相关的文章

脑外伤多由头部突然的加速或减速运动、头部快速撞击不能移动的硬物、高空坠落、跌倒、头部遭受暴力等造成的脑损伤。交通事故伤是脑外伤最常见的原因,其次为坠落伤、火器、暴力、摔倒、异物贯通、自然灾害、工伤事故等。脑外伤不同的损伤部位症状不同,包括运动、感觉、言语、视觉、听觉等方面异常。脑外伤急性期时治疗以维
晏晓陶,女,原TVB国语配音演员,曾为多部电视剧和电影进行配音。她的代表作品包括《神雕侠侣》《冤家易结不易解》《梁祝》以及2004年的《金枝欲孽》中的安茜。1994年,她为《梁祝》中的杨采妮配音,1996年为电影《甜蜜蜜》中的张曼玉配音。晏晓陶的丈夫是香港男高音歌唱家、国语配音演员黄河,他最为人所知
摄氏度是摄氏温标(C)的温度计量单位,用符号℃表示,是目前世界上使用较为广泛的一种温标。它最初是由瑞典天文学家安德斯·摄尔修斯于1742年提出的,其后历经改进。

卡拉奇(乌尔都语:كراچى,信德语:ڪراچي),是巴基斯坦第一大城市,位于巴基斯坦南部海岸、印度河三角洲西北部,南濒临阿拉伯海,居莱里河与玛利尔河之间的平原上。人口约2000万,面积3527平方公里,其中城区面积1821平方公里。[4]卡拉奇属于亚热带沙漠气候,一年大部分时间高温少雨,炎热难耐,冬季(1、2月)平均最低气温13℃,夏季(5、6月)平均最高气温34℃。雨量稀少,年平均降水量仅200毫米。[4]2019年12月26日,位列2019年全球城市500强榜单第117名。

一之濑巧是由矢泽爱著名漫画《NANA(世界上的另一个我)》中的魅力人物,TRAPNEST的队长兼贝斯,绰号大魔王。是个工作狂,所关心的东西只有TRAPNEST。

尚可名片
这家伙太懒了,什么都没写!
作者