
精选百科
本文由作者推荐

快速聚类
快速聚类
正文
SPSS的快速聚类过程适用于对大样本进行快速聚类,尤其是对形成的类的特征(各变量值范围)有了一定认识时,此聚类方法使用起来更加得心应手。
操作及分析方法
为了使粗通统计分析方法的读者也能都使用该过程进行聚类分析,我们先以小样本数据为例说明其操作及分析方法。
例12.3.1对游泳运动员进行分项。为简化问题,仅以10名运动员的三项测试数据为例。其中变量x1=肩宽/髋宽×100;x2=胸厚/胸围×100;x3=腿长/身长×100。预计按姿势分为蝶泳、仰泳、蛙泳、自由泳四类。原始数据如表12-13所示。
表12-1310名运动员的三项测试数据
操作方法分为以下几步:
(1)首先定义变量、输人数据。建立聚类工作数据文件,也称聚类分析的输入数据文件。
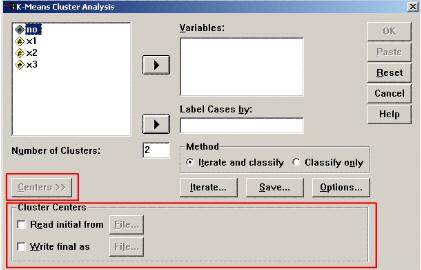
(2)按Analyze、Classify、K-Meanscluster顺序逐一单击鼠标键,最后展开对话框,如图12-20所示。
图12-20K-Meanscluster对话框
快速聚类
(3)指定分析变量和标识变量本例中标识每个观测量的变量是"no"。因此:
选择主对话框中左面变量表中的"no"。单击鼠标键使之置于光带中。
单击下面一个右箭头按钮,使变量名移到"LableCasesby:"下面的矩形框中。
选择参与聚类分析的数值型变量,单击上面一个向右箭头按钮,使选中的变量名移到右面的"Variables:"下面的矩形框中。
(4)确定分类数
系统默认的分类数为2,显示在"Numberofcluster"后面的矩形框中。按分析要求应该分为4类,将原数值2改为4。
其他参数全部选用系统默认值,无需继续操作其他按钮或图标按钮。
(5)选择聚类方法
在主对话框中的"Method"框中的两项中可以选择一种聚类方法。我们选择系统默认值。(项前圆圈中有黑点的)所涉及的选择项均使用默认值。
(6)执行Quickcluster命令,方法有两种:
①单击按钮"OK",系统立即执行该命令。
②单去按钮"Paste",激活"Syntax"窗,将"Quickcluster"命令及由其子命令和所设置的参数组成的程序生成在该窗中。
根据在主对话框中选择的标识变量、分析变量、和分类数生成以下程序:
QUICKCLUSTER
xlx2x3
/MISSING=LISEWISE
/cRITERIA=cLUSTER(4)MxITER(10)cONVERGE(.02)
/METHOD=kmeans(NOUPDATE)
/PRINTID(no)INITIAL.
③按该窗中的"Run"按钮,执行窗中的命令程序
(7)显示在输出窗中的程序运行结果如下:
表12-14初始类中心

快速聚类
表12-15各次迭代后类中心的变化
快速聚类
表12-16最终的四类的类中心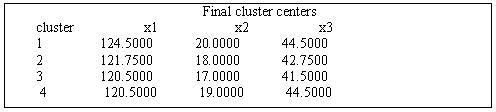
快速聚类
表12-17聚类总结
快速聚类
快速聚类相关的文章

木卫二(Europa,古希腊语:Ευρώπη),又称为欧罗巴,是木星的第六颗已知卫星,也是木星的第四大卫星。在1610年被伽利略发现后,木卫二由西门·马里乌斯独立发现。木卫二的公转轨道距离木星第五近,稍微比月球小。 木卫二是一个温和的世界,表面覆盖着冰层,底层是一片海洋。科学家认为,地球上海洋孕育了

华盛顿哥伦比亚特区本词条是多义词,共2个义项美利坚合众国的首都华盛顿哥伦比亚特区,简称华盛顿,又称华都、华府,美利坚合众国的首都,得名于美国首任总统乔治·华盛顿,靠近弗吉尼亚州和马里兰州,位于美国的东北部、中大西洋地区,是1790年作为首都而设置、由美国国会直接管辖的特别行政区划,因此不属于美国的任何一州。截至2016年,华盛顿市区面积177平方公里;2019年1月,人口约70万。华盛顿哥伦比亚特
胰岛素蛋白质激素名称胰岛素(Regular insulin)可增加葡萄糖的利用,能加速葡萄糖的无氧酵解和有氧氧化,促进肝糖原和肌糖原的合成和贮存,并能促进葡萄糖转变为脂肪,控制糖原分解和糖异生,因而能使血糖降低。此外,本品能促进脂肪的合成。抑制脂肪分解,使酮体生成减少,纠正酮症酸血症的各种症状。能促进蛋白质的合成,抑制蛋白质分解。本品和葡萄糖同用时,可促使钾从细胞外液进入组织细胞内。

尚可名片
这家伙太懒了,什么都没写!
作者


