
OCR(optical character recognition)文字识别是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,然后用字符识别方法将形状翻译成计算机文字的过程;即,对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。如何除错或利用辅助信息提高识别正确率,是OCR最重要的课题的友好性,产品的稳定性,易用性及可行性等。
OCR文字识别

OCR文字识别
Optical Character Recognition
光学文字识别的概念是在1929年由德国科学家Tausheck最先提出来的,后来美国科学家Handel也提出了利用技术对文字进行识别的想法。而最早对印刷体汉字识别进行研究的是IBM公司的Casey和Nagy,1966年他们发表了第一篇关于汉字识别的文章,采用了模板匹配法识别了1000个印刷体汉字。
早在60、70年代,世界各国就开始有OCR的研究,而研究的初期,多以文字的识别方法研究为主,且识别的文字仅为0至9的数字。以同样拥有方块文字的日本为例,1960年左右开始研究OCR的基本识别理论,初期以数字为对象,直至1965至1970年之间开始有一些简单的产品,如印刷文字的邮政编码识别系统,识别邮件上的邮政编码,帮助邮局作区域分信的作业;也因此至今邮政编码一直是各国所倡导的地址书写方式。
20世纪70年代初,日本的学者开始研究汉字识别,并做了大量的工作。中国在OCR技术方面的研究工作起步较晚,在70年代才开始对数字、英文字母及符号的识别进行研究,70年代末开始进行汉字识别的研究,到1986年汉字识别的研究进入一个实质性的阶段,不少研究单位相继推出了中文OCR产品。早期的OCR软件,由于识别率及产品化等多方面的因素,未能达到实际要求。同时,由于硬件设备成本高,运行速度慢,也没有达到实用的程度。只有个别部门,如信息部门、新闻出版单位等使用OCR软件。
1986年以后我国的OCR研究有了很大进展,在汉字建模和识别方法上都有所创新,在系统研制和开发应用中都取得了丰硕的成果,不少单位相继推出了中文OCR产品。
进入20世纪90年代以后,随着平台式扫描仪的广泛应用,以及我国信息自动化和办公自动化的普及,大大推动了OCR技术的进一步发展,使OCR的识别正确率、识别速度满足了广大用户的要求。其中以OCR为科技核心的云脉技术不断创新进取,研发了一系列OCR软件产品,并且运用在医院,学校,企业等各大市场。
由于扫描仪的普及与广泛应用,OCR软件只需提供与扫描仪的接口,利用扫描仪驱动软件即可。因此,OCR软件主要是由下面几个部分组成。
1、图像输入、预处理:
图像输入:对于不同的图像格式,有着不同的存储格式,不同的压缩方式。预处理:主要包括二值化,噪声去除,倾斜较正等
2、二值化:
对摄像头拍摄的图片,大多数是彩色图像,彩色图像所含信息量巨大,对于图片的内容,我们可以简单的分为前景与背景,为了让计算机更快的,更好的识别文字,我们需要先对彩色图进行处理,使图片只前景信息与背景信息,可以简单的定义前景信息为黑色,背景信息为白色,这就是二值化图了。
3、噪声去除:
对于不同的文档,我们对噪声的定义可以不同,根据噪声的特征进行去噪,就叫做噪声去除
4、倾斜较正:
由于一般用户,在拍照文档时,都比较随意,因此拍照出来的图片不可避免的产生倾斜,这就需要文字识别软件进行较正。
版面分析:
5、将文档图片分段落,分行的过程就叫做版面分析,由于实际文档的多样性,复杂性,因此,目前还没有一个固定的,最优的切割模型。
6、字符切割:
由于拍照条件的限制,经常造成字符粘连,断笔,因此极大限制了识别系统的性能,这就需要文字识别软件有字符切割功能。
7、字符识别:
这一研究,已经是很早的事情了,比较早有模板匹配,后来以特征提取为主,由于文字的位移,笔画的粗细,断笔,粘连,旋转等因素的影响,极大影响特征的提取的难度。
8、版面恢复:
人们希望识别后的文字,仍然像原文档图片那样排列着,段落不变,位置不变,顺序不变,的输出到word文档,pdf文档等,这一过程就叫做版面恢复。
9、后处理、校对:
根据特定的语言上下文的关系,对识别结果进行较正,就是后处理。
开发一个OCR文字识别软件系统,其目的很简单,只是要把影像作一个转换,使影像内的图形继续保存、有表格则表格内资料及影像内的文字,一律变成计算机文字,使能达到影像资料的储存量减少、识别出的文字可再使用及分析,当然也可节省因键盘输入的人力与时间。
从影像到结果输出,须经过影像输入、影像前处理、文字特征抽取、比对识别、最后经人工校正将认错的文字更正,将结果输出。

脊髓小脑性共济失调是基因变异引起的神经系统疾病,属于遗传性疾病。脊髓小脑性共济失调是家族遗传性疾病,多于青少年期和中年期发病。基因变异导致机体各系统产生功能变化,尤其引起神经病变。脊髓小脑性共济失调有多种亚型,共同的临床表现有步履不稳、肢体摇晃、动作反应迟缓、发音含糊不清等。脊髓小脑性共济失调无特殊
麦芽糖是一种由两个葡萄糖分子以α-1,4糖苷键连接而成的淀粉糖产品,也称为麦芽二糖。根据麦芽糖含量的不同,麦芽糖浆可分为普通麦芽糖浆、高麦芽糖浆和超高麦芽糖浆。麦芽糖是一种碳水化合物,由含淀粉酶的麦芽作用于淀粉而制得,可用作营养剂和培养基的配制。此外,麦芽糖也是一种中国传统怀旧小食。
塔里木河流域周围是天山南坡—昆仑山—阿尔金山等高原山区,中间是塔里木盆地。周边有大小河流一百四十多条,都发源于盆地周边高原山区的一百四十多条大小河流呈向心分布汇入盆地,大多数小河流出山区后消耗散失于绿洲和广阔的沙漠地区。
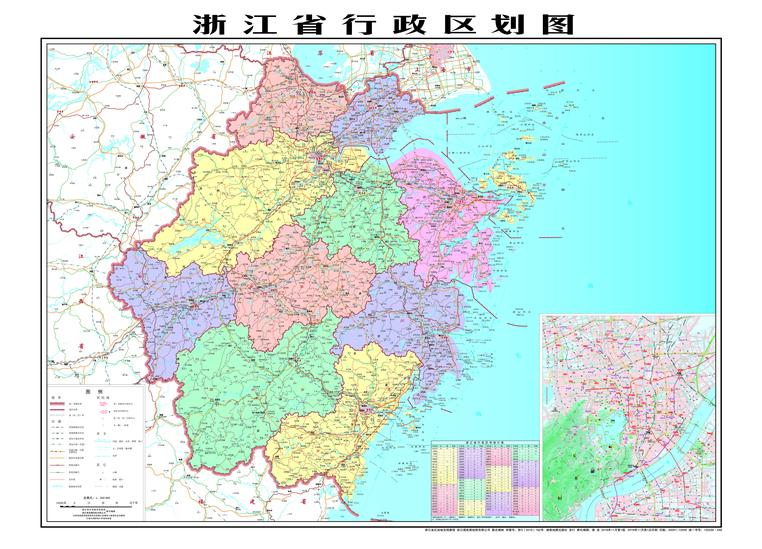
浙江本词条是多义词,共2个义项中华人民共和国省级行政区浙江省,简称“浙”,省会杭州。浙江省境内最大的河流钱塘江,因江流曲折,称之江,又称浙江,省以江名。其地处中国东南沿海长江三角洲南翼,东临东海,南接福建,西与江西、安徽相连,北与上海、江苏接壤。浙江地势由西南向东北倾斜,地形复杂。山脉自西南向东北成大致平行的三支,有“七山一水两分田”之说。浙江属典型的亚热带季风气候区。浙江是全国岛屿最多的省份,其

克里特岛希腊的第一大岛克里特岛(Κρήτη;Crete)位于地中海东部的中间,是希腊的第一大岛,总面积约8336平方公里,人口:约60.1万。行政上属于克里特大区。克里特岛是爱琴海最南面的皇冠,是美不胜收的度假之地。克里特岛位于希腊的南端,是爱琴海中最大的岛屿。距离非洲大陆仅有300公里。该岛东西长约260公里,南北宽最宽60公里,最窄只有12公里,克里特岛是一个以崎岖山地为主体的岛屿。构成岛上东

尚可名片
这家伙太懒了,什么都没写!



